This material is based upon work supported by the National Science Foundation under Grant numbers 1633157, 1633310, and 1633295.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Project Duration: 9/1/2016 - 8/31/2020.
Grant #1633295, PI Tamara Berg, UNC Chapel Hill.
Grant #1633310, PI Alexei Efros, UC Berkeley.
Grant #1633157, PI Jia Deng, Princeton University.
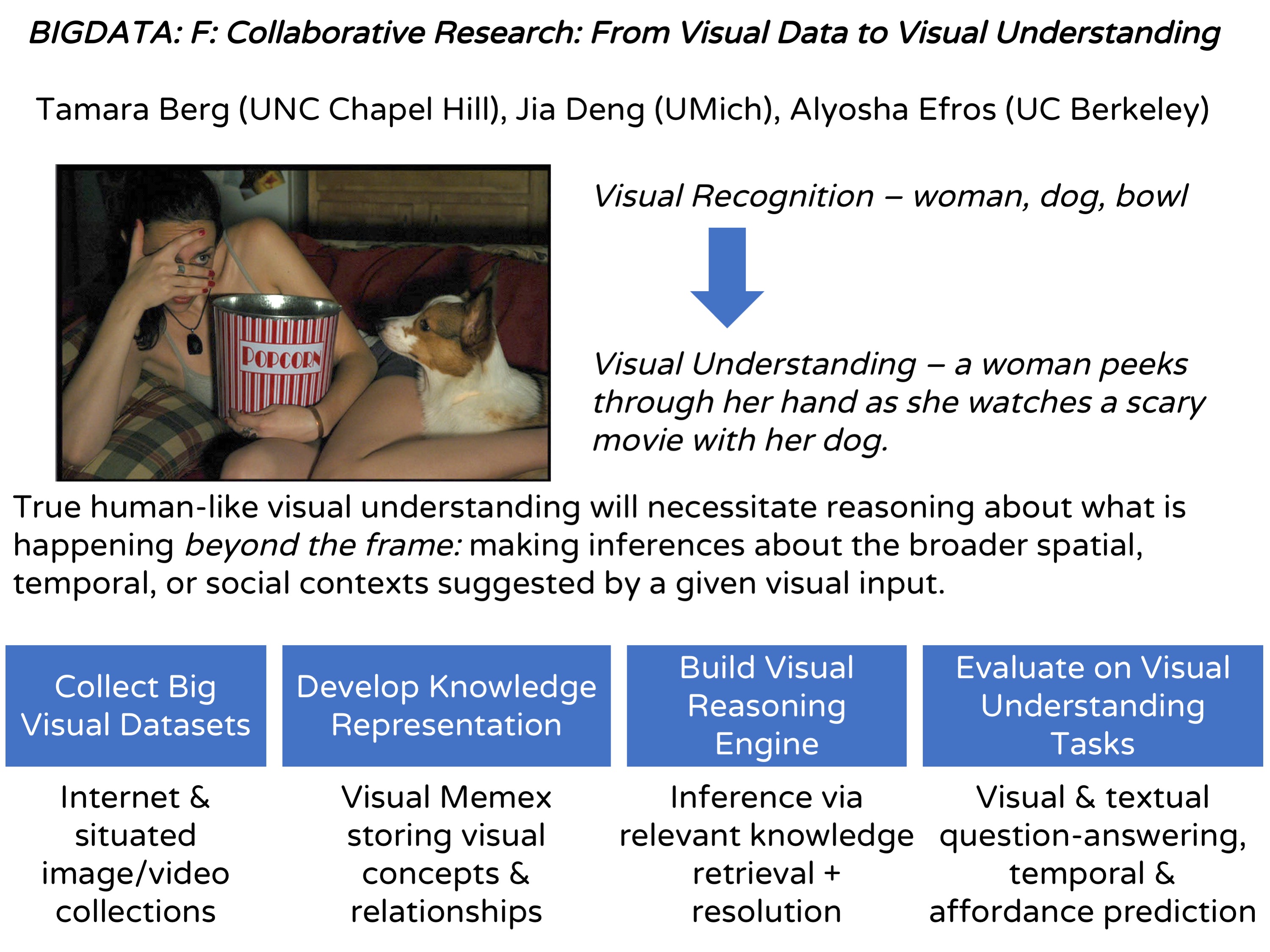
The field of visual recognition, which focuses on creating computer algorithms for automatically understanding photographs and videos, has made tremendous gains in the past few years. Algorithms can now recognize and localize thousands of objects with reasonable accuracy as well as identify other visual content, such as scenes and activities. For instance, there are now smart phone apps that can automatically sift through a user's photos and find all party pictures, or all pictures of cars, or all sunset photos. However, the type of "visual understanding" done by these methods is still rather superficial, exhibiting mostly rote memorization rather than true reasoning. For example, current algorithms have a hard time telling if an image is typical (e.g., car on a road) or unusual (e.g., car in the sky), or answering simple questions about a photograph, e.g., "what are the people looking at?", "what just happened?", "what might happen next?" A central problem is that current methods lack the data about the world outside of the photograph. To achieve true human-like visual understanding, computers will have to reason about the broader spatial, temporal, perceptual, and social context suggested by a given visual input. This project is using big visual data to gather large-scale deep semantic knowledge about how events, physical and social interactions, and how people perceive the world and each other. The research focuses on developing methods to capture and represent this knowledge in a way that makes it broadly applicable to a range of visual understanding tasks. This will enable novel computer algorithms that have a deeper, more human-like, understanding of the visual world and can effectively function in complex, real-world situations and environments. For example, if a robot can predict what a person might do next in a given situation, then the robot can better aid the person in their task. Broader impacts will include new publicly-available software tools and data that can be used for various visual reasoning tasks. Additionally, the project will have a multi-pronged educational component, including incorporating aspects of the research in the graduate teaching curriculum, undergraduate and K-12 outreach, as well as special mentoring and focused events for advancement of women in computer science.
The main technical focus of this project is to advance computational recognition efforts toward producing a general human-like visual understanding of images and video that can function on previously unseen data, unseen tasks and settings. The aim of this project is to develop a new large-scale knowledge base called the visual Memex that extracts and stores vast set of visual relationships between data items in a multi-graph representation, with nodes corresponding to data items and edges indicating different types of relationships. This large knowledge base will be used in a lambda-calculus-powered reasoning engine to make inferences about visual data on a global scale. Additionally, the project will test computational recognition algorithms on several visual understanding tasks designed to evaluate progress on a variety of aspects of visual understanding, including: linguistic (evaluating our understanding about imagery through language tasks such as visual question-answering), to purely visual (evaluating our understanding of spatial context through visual fill-in-the-blanks), to temporal (evaluating our temporal understanding by predicting future states), to physical (evaluating our understanding of human-object and human-scene interactions by predicting affordances). Datasets, knowledge base, and evaluation tools will be hosted on the project web site.
Point of Contact: Tamara Berg (tlberg -at- cs.unc.edu).
Page last updated 8/15/2019